Parser module contains functions for tokenization a word with Logo commands/data to a list of individual tokens, and then parsing it into an abstraxt syntax tree.
- Parser API (parser.h)
- Parser implementation (parser.c)
- Tokenization
- Parsing
- Parsing step 1: Processing parentheses
- Parsing step 2: Extract source line
- Parsing step 3: Analyze and set dependencies
- Parsing step 4: Check for missing or extra arguments
- Parsing step 5: Recursive parse of nested structures
- Parsing step 6: Group items into expression lists
- Parsing step 7: Merge expression lists into the result
- Function parsing
- Priorities and associativeness
Tokenization
Both data and command tokenization is performed by using cell automata and micro-programming languages. Cell automata contains states, triggers and microprograms. Transitions from state to state is done explicitely by special microprogram instruction.
States
The states define the modes of the cell automata, which corresponds roughly to the type of the token being processed. The list of available states is shown in the table below.
| Code | Mode | Description |
| S0 | Entry | An initial state when a token is about to be extracted. |
| S1 | Whitespace | A state when a whitespace sequence of characters are processed. |
| S2 | Word | A state when a word is processed. |
| S3 | Barred word | A state when a word is processed but the current position is inside bars |...|. |
| S4 | Backslashed word | A state when a word is processed but the current position is right after a backslash \. |
| S5 | Tilde | A state when characters after a tilde ~ are examined whether there is a line continuation. |
| S6 | Semicolon-Tilde | A state to examine whether a tilde ~ in a semicolon comment ; is a line continuation. |
| S7 | Semicolon | A state when a semicolon comment ; is processed. |
| S8 | Tilde-space | A state when whitespaces after a tilde ~ are observed. |
| S9 | Less | A state to examine the character after <. |
| S10 | Greater | A state to examine the character after >. |

Triggers
Triggers are the conditions that control which microprogram to run. The white trigger (EOF) is always active. The green triggers are active only while tokenization of data. The red triggers are active only while tokenization of commands.
It is assumed that tokenization of commands is done only after the source has already been tokenized as data.
| Trigger | Description |
EOF | The end of the source is reached. |
SPC | A white space is read. Whitespaces are all characters with ASCII code from 0 to 32 (i.e. SPACE) but excluding 10 (Line Feed). |
EOL | A Line Feed character is read. |
| An open square bracket |
| A closed square bracker |
| A bar |
~ | A tilde ~ is read. |
| A semicolon |
| A parenthesis |
+ - * / | A mathematical operator +, -, * or / is read and the first character in the sequence is not double quotes ". |
= | An equal sign = is read and the first character in the sequence is not double quotes ". |
< | A less sign < is read and the first character in the sequence is not double quotes ". |
> | A greater sign > is read and the first character in the sequence is not double quotes ". |
| Else | A character not falling into any of the categories above is read. |
Microprogram instructions
The instructions available in the microprogramming are simple atomic action which can be combined to build a more complex token processing. Each instruction is coded through a bitmask:
| Instruction | Description |
| ~ | Write tilde ~ to the output stream. |
| W | Write the current character to the output stream only if the mode is not S3 or is S3 but is neither S6 or S7. |
| A | Advance to the next character. |
| A2 | Advance to the character after the next character. |
| D | Set dirty flag (barred and/or backslashed word). |
| M | Set mutated flag (word must be copied - has comment or line continuation). |
| U2 | The return from the next call should go to S2. |
| U | The return from the next call should return to the current state. |
| Uu | The return from the next call should return to the caller of the current state. |
| Sn | Switch to state N. |
| TE | Emit TOKEN_END and end tokenization. |
| TS | Emit TOKEN_SPACE and goto S0 |
| TW | Emit TOKEN_WORD and goto S0 |
| TL | Emit TOKEN_LINEEND and goto S0 |
| TO | Emit TOKEN_OPEN and goto S0 |
| TC | Emit TOKEN_CLOSE and goto S0 |
| O | Return to the calling mode. |
| R | Remember current position as error position. |
| E | Generate an error message. |
Microprograms
Each pair of state-trigger defines a unique microprogram which is executed if the designated trigger is activated while the process in the designated state. Every microprogram is encoded into a number which bits show which microinstructions are included. The order of the microinstruction execution is fixed as shown in the next table.
| S0 Entry | S1 Space | S2 Word | S3 |...| | S4 \... | S5 ~... | S6 ;...~ | S7 ;... | S8 ~ ... | S9 < | S10 > | |
EOF | TE | TS | TW | E | E | E | E | O | E | TW | TW |
SPC | AS1 | A | TW | WA | WAO | AS8 | A | A | A | TW | TW |
EOL | ATL | TS | TW | WA | WAO | AO | AO | O | AO | TW | TW |
| ATO | TS | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
| ATC | TS | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
| WAD RU2S3 | TS | WAD RUS3 | WAO | WAO | ~O | O | WAD RUS3 | ~ TW | TW | TW |
\ | WAD RU2S4 | TS | WAD RUS4 | WAUS4 | WAO | ~O | O | A2 | ~ TW | TW | TW |
~ | ARUS5 | TS | AMR US5 | WA | WAO | ~O | O | AMR UUS6 | ~ TW | TW | TW |
| AUS7 | TS | AMUS7 | WA | WAO | ~O | O | A | ~ TW | TW | TW |
| else | WAS2 | TS | WA | WA | WAO | ~O | O | A | ~ TW | TW | TW |
| WATW | TS | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
+ - * / | WATW | TS | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
= | WATW | TS | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
< | WAS9 | TW | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
> | WAS10 | TW | TW | WA | WAO | ~O | O | A | ~ TW | TW | TW |
Parsing
The parsing function parse is used to convert a list of tokens into an abstract syntax tree. This is done by converting the list into a completely parenthesised prefix-notation (LISP-notation). The parsing goes through several steps:
- Process parentheses
- Extract source line
- Build expressions
- Analyze and set dependencies
- Check for missing or extra arguments
- Recursive parse of nested structures
- Group items into expression lists
- Merge expression lists into the result
The steps (without the first one) are repeated as long as there is input source.
Parsing step 1: Processing parentheses
Initially parentheses appear in the input as separate tokens. This step identifies all parentheses pairs and converts their contents into a subexpression. This step can generate an error ERROR_INCOMPLETE_PAIR if parentheses do not match. The step is implemented in function parentheses.
Parsing step 2: Extract source line
Input source, which is assumed to be tokenized, is processed line-by-line. This step is responsible for identification of a line and extractive line data into internal array. The step is implemented in function get_line().
The end of a source line is determined examining the element following it. If it has its FLAG_NEWLINE set and is not list-constant, then it starts a new line. The list-constant test is done to allow lists to be placed on a new line without framing parentheses:
Line extraction also extract and preprocesses elements and initializes a set of local arrays:
data[] - atoms from the tokenized and parenthesized inputvars[] - pointers to functions corresponding to atoms indata[]. If the atom does not correspond to a function name, then the pointer isNULL.pris[] - priority of an item. If the item is a function then its priority is the priority of the function. Otherwise the priority is the maximum priority PRIORITY_MAX.usedby[] - indexes are items which functions use the current item as parameter. For example ifusedby[4] is 2, then item 2 in the arrays uses item 4 as a parameter. Items which are not used by any other have value -1. Initially all items are unused.largs[] - number of unprocessed left arguments. A positive value means that the item need more parameters - i.e. it needs more other items whichusedbyvalue point to this item. Initially the value oflargsis taken from the default number of parameter of the corresponding function (if the item is a function), or 0 otherwise.rargs[] - similarly tolargs, but for the right arguments.
The next figure shows the values of these arrays for:
make "a :x+sin :y-1

The get_line function also processes FLAG_INFINITE_ARGS and FLAG_CAN_BE_UNARY flags.
If a function inside parentheses has FLAG_INFINITE_ARGS set, then its rargs are set to -1, which means that it can accept infinite number of parameters. When parameters are found the rargs value is decreased. When rargs becomes 0 further search is stopped. Setting rargs to -1 does not really make number of parameter infinite, but sets the limit to up to 231.
When several functions inside single pair of parentheses may have infinite number of arguments then only the leftmost one's rargs are set to -1, thus
(word 1 2 3 word 4 5 6)
is treated as
(word 1 2 3 (word 4 5) 6)
The automatic decision of arity is controlled as described in the table below:
| Case | Spaces exist | Arity |
space + space | Before and after operator | Binary |
space + | Only before operator | Unary |
+ space | Only after operator | Binary |
+ | No spaces around the operator | Binary |
Parsing step 3: Analyze and set dependencies
This step of the parser determines the relation between functions and their arguments - i.e. it discovers which item to which function belongs. A function that uses another item as argument is considered dependent on it.The process scans all the items and sets some of the dependencies. Then it repeats the scan until all dependencies are resolved. This rescanning in needed because setting some dependencies can invalidate previously set lower-priority dependencies.
For each item during the scan the following things are done:
- It scans to the left of the item looking for
largsitems which are not used, or which are used by not higher priority functions. Scanning stops if the beginning of the array is reached, if a command is reached (a command cannot be an argument), or the needed number of left arguments is reached. - It scans to the right of the item looking for
rargsitems which are not used, or which are used by lower priority functions. Scanning stops if the end of the array is reached, if a command is reached (a command cannot be an argument), or the needed number of right arguments is reached.
Note that both substeps above are almost identical. The differences are in the direction of scanning and how priorities are compared (not higher is different from lower). The next figure shows the values of the parse arrays after this step. The most important array, i.e. usedby[], determines all set dependencies. They are visualized with arrow pointing from arguments to functions that use them.
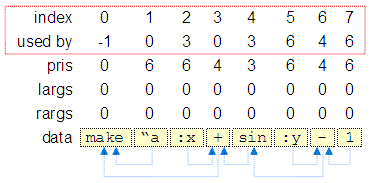
Parsing step 4: Check for missing or extra arguments
After the dependencies are set, the system checks whether there are missing or extra arguments. Missing arguments happen when a function cannot find all its arguments, either because there are no more items, or they are used by other higher-priority functions.
This step scans the parse arrays once and does these checks:
- If there are more then one free item (i.e.
usedby=-1) in a not top-most level (i.e. the items are inside parentheses (...) ), then ERROR_CROWDED_EXPRESSION error is generated pointing to the second free item. - If there are unset left arguments (
largs!=0) and FLAG_CAN_BE_UNARY is not set, then ERROR_MISSING_LEFTS error is generated. - If there is unset exactly one right argument (
rargs==1) and FLAG_MAY_SKIP_LAST_ARG is set then the item is accepted without objection. - If there are unset right arguments (
rargs!=0) and FLAG_INFINITE_ARGS is not set then ERROR_MISSING_RIGHTS error is generated.
Parsing step 5: Recursive parse of nested structures
Some structures require parsing them recursively. Such structures are all nested subexpressions, functions in parentheses and command-list arguments.
Nested subexpressions, i.e. expressions in parentheses, as well as functions in parentheses are processed in the same way - their items are parsed by recursive call to parse as if they are a standalone source. In the next example (:B+1) is a subexpression:
MAKE "A (:B+1)*:Y
Examples of functions in parentheses are:
Command-list arguments are arguments which are list of commands. Such arguments are typical for control structures like IF, REPEAT, WHILE, RUN. Commands which have command-arguments have their FLAG_PROCESS_ARGS set. The system checks the actual arguments of such commands and reparses all of them which are list constants. Arguments which are expressions will be reparsed during execution. The second input of IF in the next example will be reparsed at compile time, while the third - at runtime:
IF :A>:B [PRINT "LESS] :ELSECMD
Parsing step 6: Group items into expression lists
This step coverts all word items into numeric (if possible). Then it converts all items (numeric and non-numeric) into one-element expression lists then appends each item to the list of the function that uses it. The result after such grouping of the items from the previous figure is shown below:
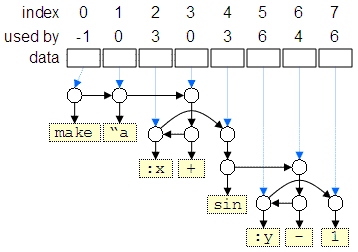
When the list structure is ordered, it represents the list as a syntax tree in a prefix LISP notation - see the next figure.
The expression shown above is equivalent to:
(make "a (+ :x (sin (- :y 1))))
which is much easier to analyzed and compiled into machine code.
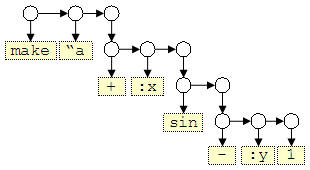
Parsing step 7: Merge expression lists into the result
When all individual expression lists are complete, the system collects the top-most of them and merges them into the resulting list of parse. Generally one line produces one expression list, however, some lines may produce several, like in the example below:
MAKE "A 1 MAKE "B 2
which becomes:
(MAKE "A 1) (MAKE "B 2)
after grouping and thus provides two lists to be merged to the result.
Function parsing
Function parsing is more than just parsing a list of commands. The main difference is that the source may contains local functions which have to be parsed recursively. The complete function parsing is implemented in function build_syntax_tree and uses the plain parsing described in the previous section. follows the algorithm for function parsing:
- tokenizes the BODY of the function
- extracts all
TO...ENDdefinitions and creates corresponding local functions - parses the BODY of the function
- parse recursivelly all local functions
This algorithm ensures that the number of inputs of all functions is known before converting any piece of source code into an abstract syntax tree. This is particularily necessary for functions which call themselves recursively.
Priorities and associativeness
All functions, command, operators, constants and variable references have default priority, which is used to parse a list of tokens into a syntax tree.
Priorities are automatically assigned depending on the type of the function. User's functions are assigned PRIORITY_CMD or PRIORITY_FUN depending on the usage of OUTPUT command in their definitions.
The priority of primitive functions is determined according to the flags. Functions with FLAG_PRIORITY_MUL, FLAG_PRIORITY_ADD, FLAG_PRIORITY_CMP, or FLAG_PRIORITY_LOG flags get the priorities PRIORITY_MUL, PRIORITY_ADD, PRIORITY_CMP, or PRIORITY_LOG respecively.
Functions with FLAG_FUNCTION flag get priority PRIORITY_FUN (and this does not depend on the value of the FLAG_COMMAND flag).
Functions with FLAG_COMMAND and without FLAG_FUNCTION get priority PRIORITY_CMD.
The hierarchy of priorities is the following:
| Element | Priority | Constant |
| Constants and variable references | 6 | PRIORITY_VAR |
Multiplicative operators: * / | 5 | PRIORITY_MUL |
Additive operators: + - | 4 | PRIORITY_ADD |
| Functions | 3 | PRIORITY_FUN |
| Compare operators: < = > <= >= <> | 2 | PRIORITY_CMP |
Logical operators: not and or | 1 | PRIORITY_LOG |
| Commands | 0 | PRIORITY_CMD |
The associativeness of a function determines the order of processing and execution among other functions with the same priority. The parser sets the associativeness depending on the number of arguments of the function.
| Left args | Right args | Order |
Suffix functions are always grouped left-to-right, i.e. 4 g f is parsed as ((4 g) f). Currently there are no primitive suffix functions. | ||
Prefix functions are always grouped right-to-left, i.e. f g 4 is parsed as (f (g 4)). All primitive functions are prefix functions. | ||
Infix operators with the same priority are processed as suffix functions: left-to-right, i.e. 1+2+3 is parsed as ((1+2)+3). | ||
Functions without arguments have no preference on their order of grouping, as long as each function is grouped alone. Such functions are PI and BYE. |
Two functions with the same priority are ordered according to their associativeness - left-to-right functions are grouped before right-to-left functions.